摘要: 最近游戏上线,开始第一次维护真正的游戏服务,同时也开始面对服务器可用性的压力。虽然目前处于 Techinical Launch,目前大约不到 2K 的 UV,但是对于服务器来讲还是有不少压力。
EBS动态扩容
遇到的第一个问题就是 15G 的 EBS(ELASTIC BLOCK STORE) SSD 被占满了,要说 AWS 的服务器虽然贵,但是贵有贵的道理,SSD被占满的情况下服务器服务依然正常,只是日志无法再写入了。首先想到为 EBS 扩容,如何保证服务不停止,动态的为 EBS 扩容呢?AWS 官方文档为了介绍相关方案。当然也可以参考其他文章比如: Tutorial: how to extend AWS EBS volumes with no downtime,不过还是官方文档更加可靠,毕竟是线上系统。而且需要理解所有操作的内部原理,保证对 live server 的完全掌控。
整个过程分为 4 步
- AWS Console EBS 扩容操作
- 确认文件系统
- 扩展分区
- 扩展文件系统
AWS Console EBS 扩容操作
这一步的目标就是为 EBS 增加容量,类似于在物理上为服务器增加容量,比如电脑硬盘有 500G,我们初始只使用了 100G,还有 400G 处于未使用状态,但是发现不够用了,需要再增加 50G,这一步就类似于增加 50G。只不过 AWS 提供了一个无限的总容量可供扩容,按需付费使用。
通过 EC2 我们可以直接定位到对应的 EBS,对于有多个 EC2 instance 更加方便,不容易出错。
在 EC2 列表找到对应需要扩容的 instance,查看 Root Device 信息,这里只有一块 EBS,如果有多块,需要确认扩容哪一块:
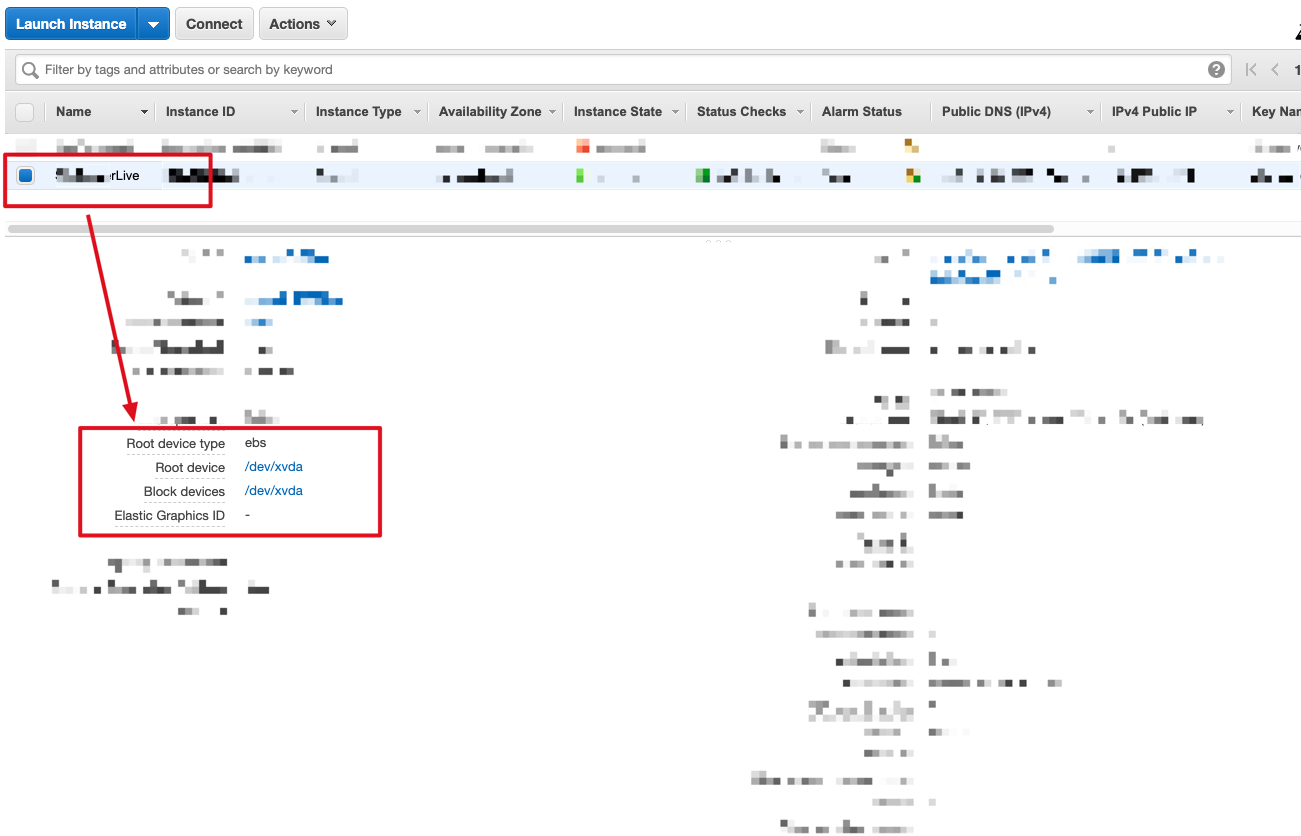
点击link,弹出悬浮窗口,通过上面的链接可以直到 EBS 页面
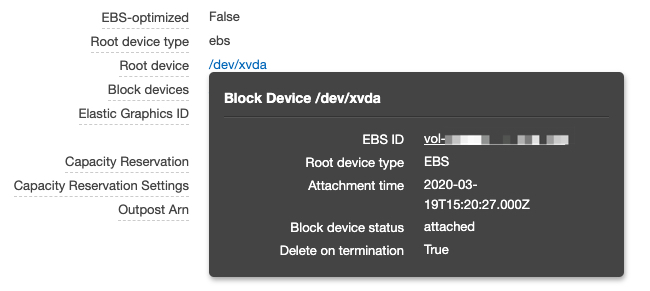
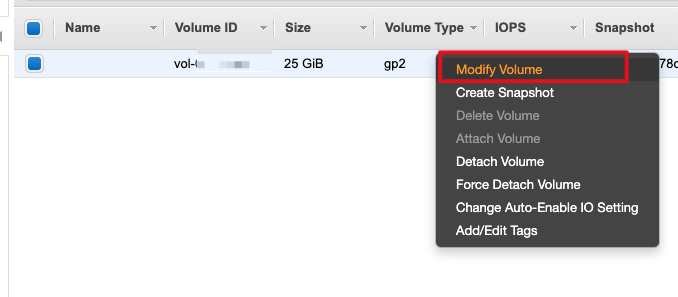
EBS 列表已经是经过筛选的结果,直接在 volume 上右键选择 Modify Volume,开始扩容:
按照需求增加容量:
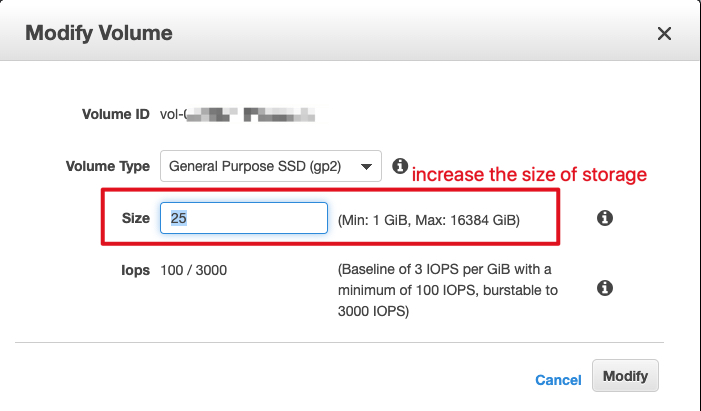
点击 Modify,弹出确认窗口,并确认
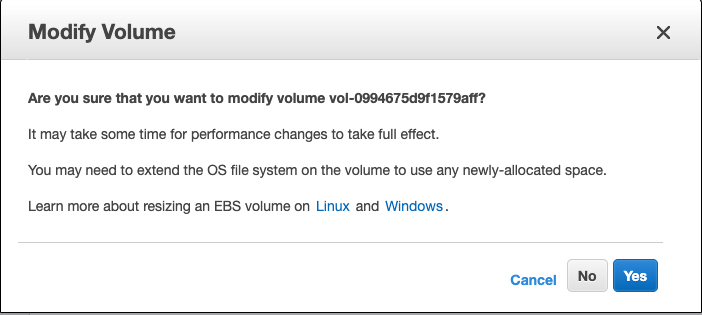
Yes 确认
验证
完成上述步骤后,我们可以 SSH 到 EC2 查看效果,可以通过 lsblk 命令查看硬盘信息:
1 | [ec2-user@ip ~]$ lsblk |
我们可以看到,硬盘总空间已经变成 20G,而使用的 / 根分区只使用 15G,说明我们已经完成 5G 的扩容。
lsblk: list block devices.
lsblk命令用于列出所有可用块设备的信息,而且还能显示他们之间的依赖关系,但是它不会列出RAM盘的信息。块设备有硬盘,闪存盘,CD-ROM等等。
确认文件系统
硬件准备好后,还需要在 Linux 上系统上进行一些维护。首先我们需要确认文件系统。常见的有两种 XFS 和 ext4。目前主流的是 XFS 系统,配备 NVMe 高性能 SSD 硬盘。
Example: File Systems on a Nitro-based Instance
The following example shows a Nitro-based instance that has a boot volume with an XFS file system and an additional volume with an XFS file system.
1 | [ec2-user ~]$ sudo file -s /dev/nvme?n* |
Example: File Systems on a T2 Instance
The following example shows a T2 instance that has a boot volume with an ext4 file system and an additional volume with an XFS file system.
1 | [ec2-user ~]$ sudo file -s /dev/xvd* |
扩展分区
如果 EBS Volume 包含分区 Partition,需要将 Partition 扩展到新的 Volume 容量。 使用 lsblk 检测信息,使用 growpart 扩展分区。官方文档给出了两个例子
Partitions on a Nitro-based Instance
扩展前
1 | [ec2-user ~]$ lsblk |
- 该案例有两个 volume :
nvme0n1和nvme1n1,其中nvme0n1分配到了根路径/,nvme1n1用于数据盘/data - 我们扩容的 volume 是
nvme0n1,nvme0n1有一个分区nvme0n1p1。我们可以看到,扩容后 voumne 是 16G,但是分区仍然是 8G。这就说明我们需要将分区扩展到我们扩容后的容量。 - 对于
nvme1n1,没有分区,所有完成扩容后,直接显示了新的容量。
下面我们通过 growpart 来完成扩展分区到 volume 空间
1 | [ec2-user ~]$ sudo growpart /dev/nvme0n1 1 |
命令分析: 这里 growpart 使用非常简单,只需要两个参数:
growpart - extend a partition in a partition table to fill available space
DISK
The device or disk image to operate on
PARTITION-NUMBER
The number of the partition to resize (counting from 1)
所以这里的意思是,我们将设备 /dev/nvme0n1 的分区 1 扩展到整个设备可用空间。也就是将分区 nvme0n1p1 扩展到 /dev/nvme0n1整个可用空间。
我们可以通过 lsblk 重新显示信息:
1 | [ec2-user ~]$ lsblk |
nvme0n1p1 新的 SIZE 已经和 nvme0n1 完全一样了。
Partitions on a T2 Instance
这里简单的介绍官方文档流程。
为扩展前:
1 | [ec2-user ~]$ lsblk |
xvda1 和 xvdf1 扩展
1 | [ec2-user ~]$ sudo growpart /dev/xvda 1 |
扩展后:
1 | [ec2-user ~]$ lsblk |
实际案例
扩展前
1 | $ lsblk |
扩展
1 | $ sudo growpart /dev/nvme0n1 1 |
扩展后
1 | $ lsblk |
扩展文件系统
完成上一步后,如果通过 df -h 会发现可以空间并没有增加,因为完成分区扩展后,还需要进一步扩展文件系统。同样这一步也根据不同的文件系统操作不同:
Example: Extend an XFS file system
操作前
1 | [ec2-user ~]$ df -h |
xfs_growfs, xfs_info - expand an XFS filesystem
xfs_growfs expands an existing XFS filesystem (see xfs(5)). The mount-point argument is the pathname of the directory where the filesystem is mounted. The filesystem must be mounted to be grown (see mount(8)). The existing contents of the filesystem are undisturbed, and the added space becomes available for additional file storage.
-d | -D size
Specifies that the data section of the filesystem should be grown. If the -D size option is given, the data section is grown to that size, otherwise the data section is grown to the largest size possible with the -d option. The size is expressed in filesystem blocks.
这里我们使用 -d 的默认值,扩展到最大可用容量。
扩容后:
1 | [ec2-user ~]$ df -h |
Example: Extend an ext2, ext3, or ext4 file system
操作前
1 | [ec2-user ~]$ df -h |
操作
1 | [ec2-user ~]$ sudo resize2fs /dev/xvda1 |
操作后:
1 | [ec2-user ~]$ df -h |
实际案例
1 | $ df -h |
扩展
1 | $ sudo xfs_growfs -d / |
扩展后:
1 | $ df -h |
寻找罪魁祸首
下面介绍一下如果搜索空间占用问题,这里主要是通过命令逐层搜索空间占用:
根路径,这里通过 grep 的正则表达式只过滤带有 G 的字符串,其他占用少的就过滤掉。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18$ sudo du -h / | grep [0-9]G
du: cannot access ‘/proc/28031/task/28031/fd/3’: No such file or directory
du: cannot access ‘/proc/28031/task/28031/fdinfo/3’: No such file or directory
du: cannot access ‘/proc/28031/fd/4’: No such file or directory
du: cannot access ‘/proc/28031/fdinfo/4’: No such file or directory
2.1G /var/lib/docker/containers/xxx
2.1G /var/lib/docker/containers
1.1G /var/lib/docker/overlay2
3.1G /var/lib/docker
3.1G /var/lib
3.7G /var
1.2G /usr
1.6G /home/ec2-user/server-composer/live/logs
1.6G /home/ec2-user/server-composer/live
1.6G /home/ec2-user/server-composer
1.6G /home/ec2-user
1.6G /home
6.5G /
我们发现 3.7G /var 是空间占用最大的,继续搜索
1 | $ sudo du -h /var/ | grep [0-9]G |
可以发现是某个 container 占用最大,继续搜索
1 | $ sudo ls -halt /var/lib/docker/containers/xxx |
最终发现居然是一个 json.log 文件十分巨大,这个文件是 docker container 的日志文件,由于我们的日志在 console 也输出导致其越来越大。所以需要维护和清理。
其他命令参考
1 | df -h |
解决根本问题
目前解决方法有两个
- 定期清理 container 的 xxx-json.log 文件
- docker-compose 限制日志文件大小及数目
后一种方法更好,但是需要重启 container,所以目前采用前一种方法。
定期清理 container 的 xxx-json.log 文件
原理就是通过 echo 将文件清空。当然我们已经定位了日志文件,可以手动清理,但是如果 container 较多,不太容易实现自动化,通过搜索发现 docker inspect 命令可以帮助完成日志文件名搜索的过程。
简答来说,只需要知道 container name 或者 id,然后通过如下命令既可清除当前的日志:
1 | echo "" > $(docker inspect --format='{{.LogPath}}' <container_name_or_id>) |
参考如下:
为了定期清理,配置 cornjob 每一个小时清理一次:
1 | # 需要管理员权限 |
编辑配置
1 | 0 * * * * echo "" > $(docker inspect --format='{{.LogPath}}' 7a53309889a2) |
这样就可以每个小时处理一次。cornjob 配置: every-hour
如果希望产看 cornjob 的执行历史,可以通过日志文件来查看,可以看到对应的命令被执行的记录:
1 | cat /var/log/cron |
docker-compose 限制日志文件大小及数目
参考
https://medium.com/@Quigley_Ja/rotating-docker-logs-keeping-your-overlay-folder-small-40cfa2155412
https://docs.docker.com/config/containers/logging/configure/#configure-the-logging-driver-for-a-container
https://stackoverflow.com/a/42883229/2000468
1 | version: '2' |
为 compose 的 service 增加如下配置:
1 | my-app: |
json-file 选项介绍: https://docs.docker.com/config/containers/logging/json-file/
- json-file The logs are formatted as JSON. The default logging driver for Docker.
- max-size The maximum size of the log before it is rolled. A positive integer plus a modifier representing the unit of measure (k, m, or g). Defaults to -1 (unlimited). —log-opt max-size=10m
- max-file The maximum number of log files that can be present. If rolling the logs creates excess files, the oldest file is removed. Only effective when max-size is also set. A positive integer. Defaults to 1. —log-opt max-file=3