摘要: 本文介绍如何在 AWS 使用 Data Pipeline 跨 Region 迁移 DynamoDB
需求
假设我们有一个table 名称 Evolution
origin table:
name: Evolution
region: ap-northeast-1
destination table:
name: qa_Evolution
region: ap-southeast-1
我们需要将 origin table 数据 migrate 到 destination table
操作
基础
搜索 DataPipeline
创建 Pipeline

导出
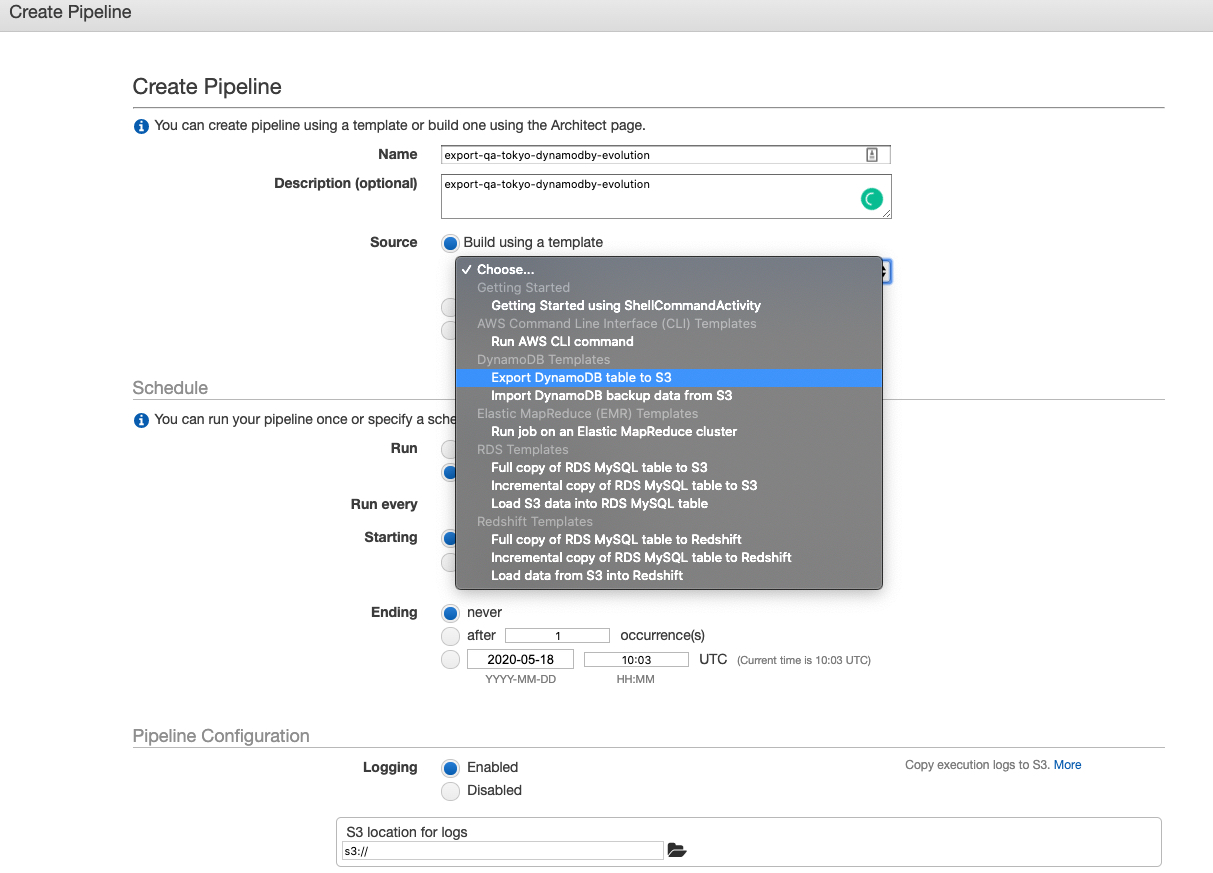
这里主要注意几个问题:
- 选择 Export DynamoDB table to S3
- Source DynamoDB table name 需要填入 origin table name: Evolution
- Region of the DynamoDB table 需要填入 origin table region:ap-northeast-1
- 需要提前创建一个 S3 bucket 来存放数据
- 选择
on pipeline activation表示该 pipeline 只运行一次 Pipeline Configuration可以配置log 的 S3 bucket,如果放在了同一个目录,需要注意区分哪个数据哪个是日志。
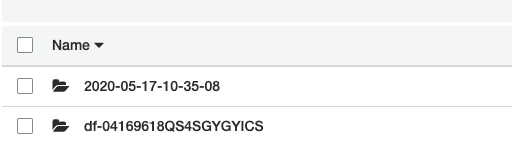
带有 df-xxxx 是日志文件,第一个日期格式的文件夹是数据,这一点我们可以参考 https://docs.aws.amazon.com/datapipeline/latest/DeveloperGuide/dp-importexport-ddb-pipelinejson-verifydata2.html。
数据文件预览
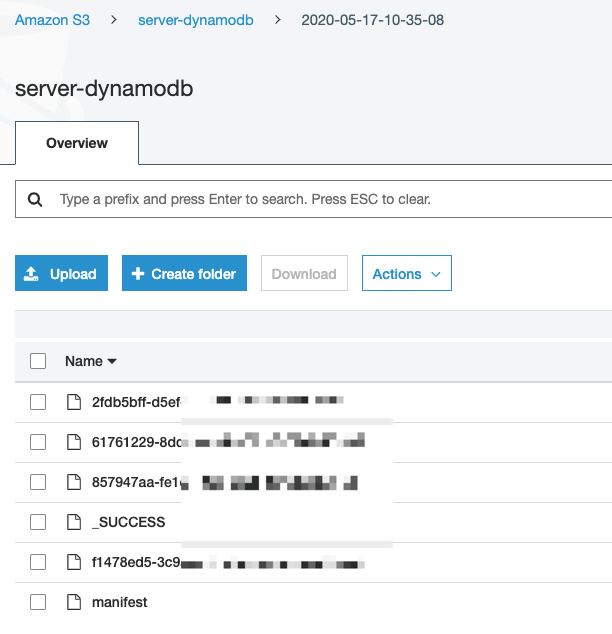
导入
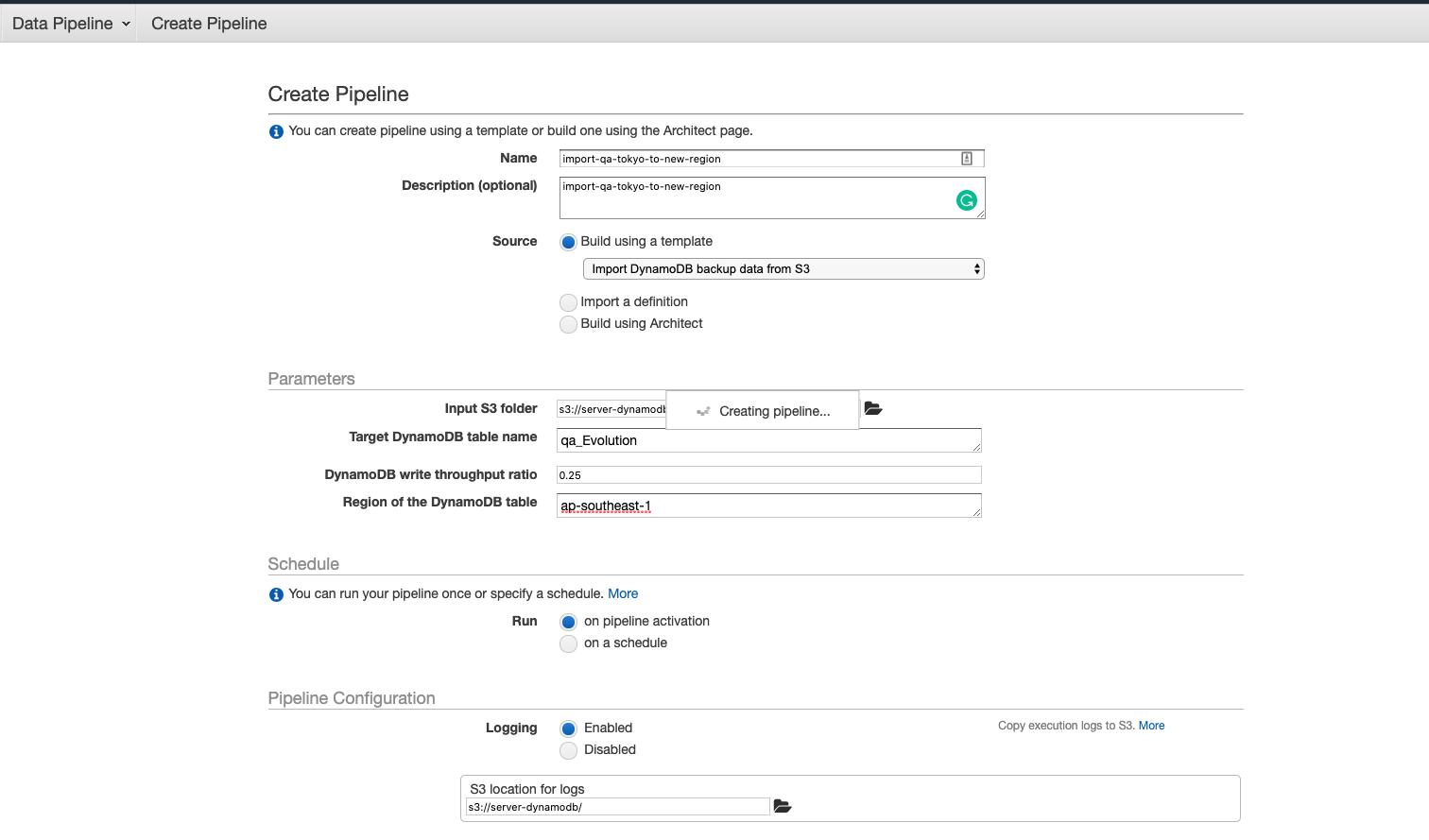
这里主要注意几个问题:
- 选择 Import DynamoDB backup data from S3
- Target DynamoDB table name 需要填入 destination table name: qa_Evolution
- Region of the DynamoDB table 需要填入 destination table region:ap-southeast-1
- Input S3 folder 一定要注意需要选择数据文件夹,别错选为日志文件夹。
- 选择
on pipeline activation表示该 pipeline 只运行一次
等到完成后,我们就可以拷到 destination table 数据完全后 origin table 一致了。
注意事项
- 由于每次运行 Pipeline 都要创建运行环境,所以需要等待一段时间才会执行,这时候的状态是
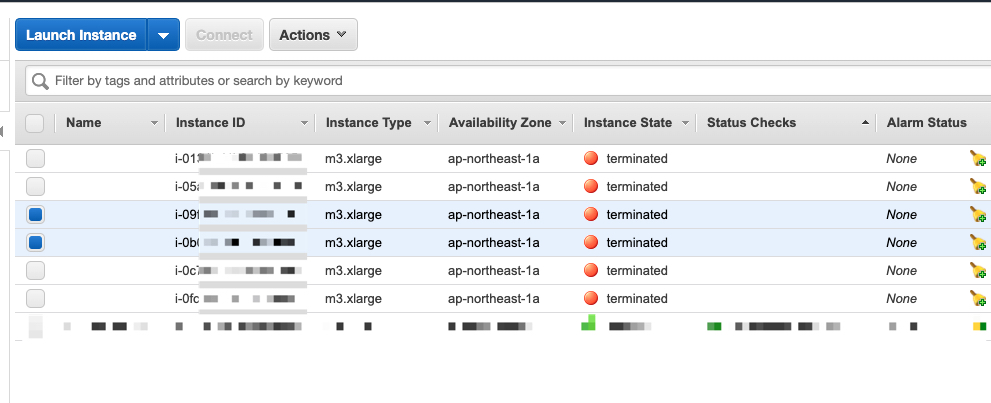
WAITING_FOR_RUNNER - 每次运行实际上是运行在一个 EC2 的节点,如果我们在这时候打开 EC2 面板,我们会发现有两个 M3.xlarge 的 EC2 instance 在创建并初始化,所以这里
WAITING_FOR_RUNNER所等待的就是这个节点。该节点在运行完成后会被 terminated。另外这个 EC2 instance 是在目标 DynamoDB 所在 Region 创建。
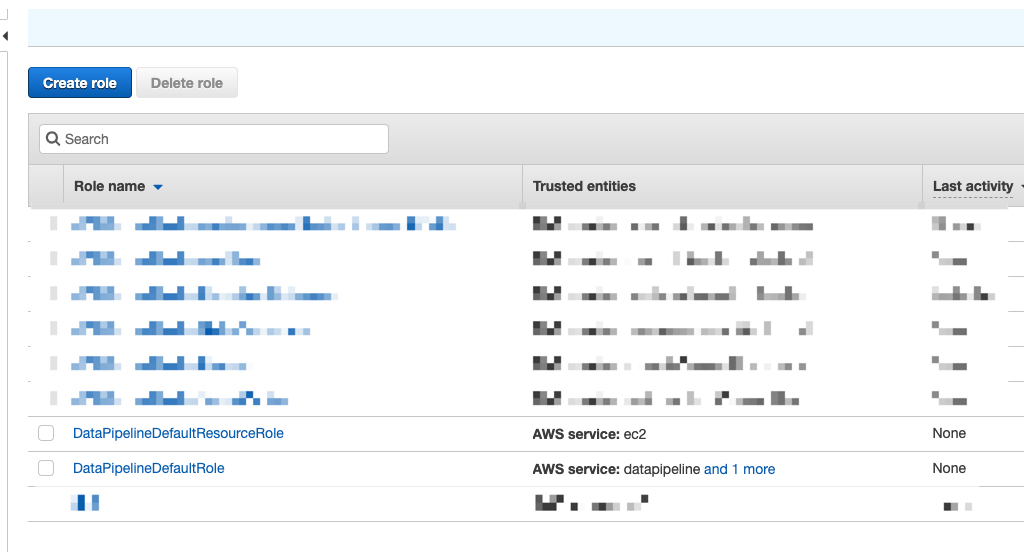
如果第一次运行失败,原始显示 IAM Role 不存在,说明之前从来运行过 Pipeline,按照文档需要手动创建,但是实际上虽然第一次运行失败了,但是会自动创建两个 Roles。所以第一次失败后,只需要再重试一次就行了
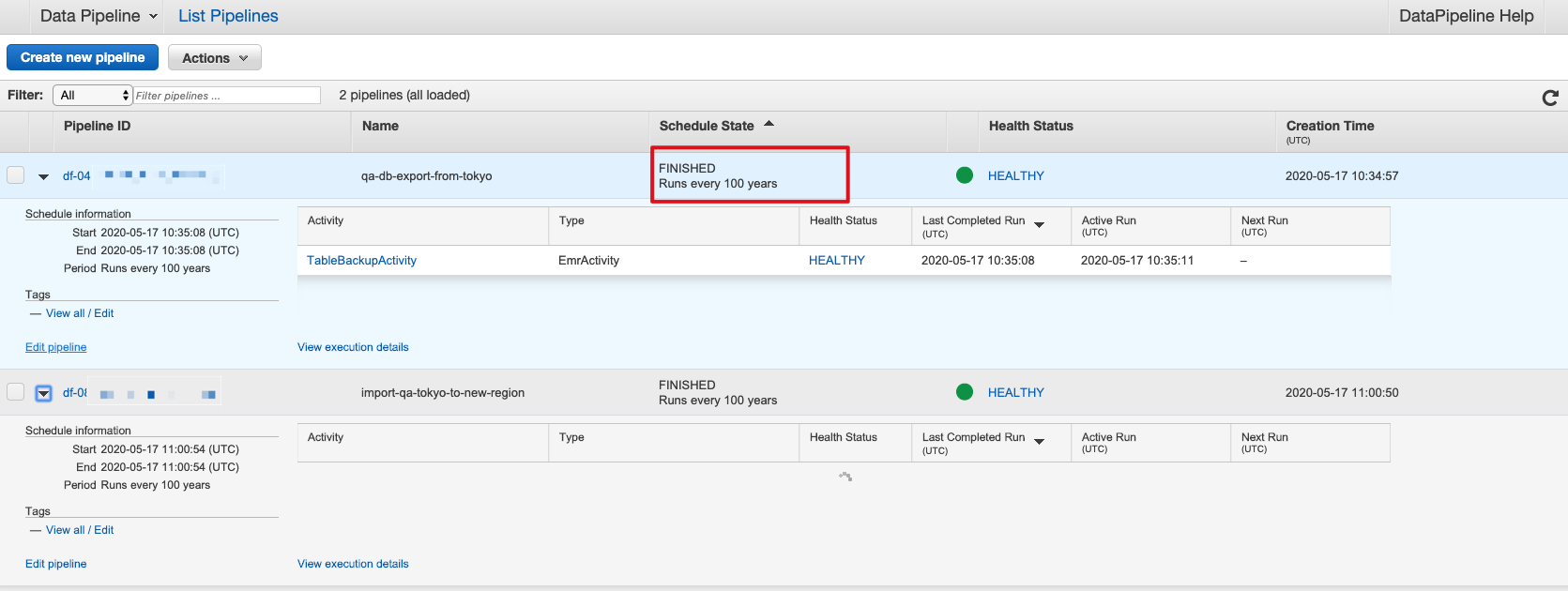
在创建的时候会有一个提醒,说是有 warning 要不要继续,我们可以选择继续。这个 warning 一般是一个参数,设置该 pipeline 会在多长时间后结束,这个参数避免我们的任务出错导致 instance 资源长期被占用。
- Pipeline 虽然是执行一次,但是根据信息我们看到实际上每 100 年运行一次,而对应的 instance 应该被 terminated。
参考文档
https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/DynamoDBPipeline.html